在学习笔记一里已经掌握了基本的contains语法和freetext语法的用法,但是面对一些复杂的操作,基本的包含语法是不够用的,如果我们想要查询含有“世界”或“末日”的所有字符串集合,那么无论是contains([column],'世界末日')或者freetext([column],'世界末日')都不能很好的工作,当然contains本身是可以含有条件的,因此有两个解决方案。
多条件查询
第一个就是传统的where多条件查询,加上两个contains语句,然后用or连接
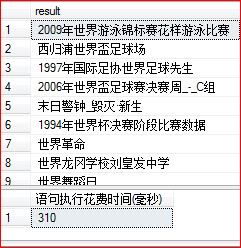
select [Column] as [result] from Sample where contains([Column],'世界') or contains([Column],'末日')
执行结果如下:
现在,介绍如何直接使用一个contains语句实现多条件查询,语法的结构如下
contains([Column],'"keyword1" and "keyword2" and ......')
contains([Column],'"keyword1" or "keyword2" or ......')
contains([Column],'("keyword1" or "keyword2") and ......')
其实也就是在两个单引号内实现多条件,and表示交集,or表示并集,我们运行如下T-SQL
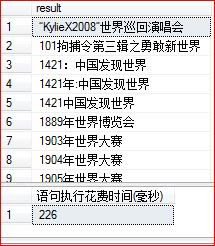
select [Column] as [result] from Sample where contains([Column],'"世界" or "末日"')
执行结果如下:
两次查询均返回了1820条记录,可以看到,排在前面的记录两者是不一样的,因此这两种方式的查询在底层的执行方式是不一样的,往往把条件都放在一个contains里会有更高的效率。
要注意的是,freetext本身就是模糊查询了,它不能再带有条件,如果想尝试在freetext里加入条件语句是没有意义的,不会返回任何结果。
现在总结一下contains和freetext,可以看到,使用这两个查询方法很简单,效率较高,但是它们一个很大的不足:
contains和freetext不会限定返回结果的数量,而是将满足条件的全部返回
这会带来两个比较重要的问题,
1、我们会得到很多无用的结果,同时如果返回结果过多,也会极大影响查询效率
2、返回的结果是无序的,并没有按照预想的如“相似程度”进行排序,导致最好的查询结果往往不再最前面
为了克服这样的问题,就可以使用containstable和freetexttable语法,这两个查询方法可以限定返回结果的数量,同时能赋予一个rank函数(相似度函数)返回rank最大的n个结果,这就是著名的top_n_by_rank argument
containstable、freetexttable
使用containstable和top_n_by_rank需要使用表的内连接操作,内连接也称为等同连接,返回的结果集是两个表中所有相匹配的数据,用on进行连接。我们让containstable返回的结果集作为一个表k,该表拥有两个字段,一个是key字段,一个是rank字段,在查询时需要将key字段与查询字段中的一个主键(唯一字段)相进行连接,如下
SELECT [Column] as [result] From wiki --查询Column字段的记录,该字段是唯一字段,并且已建立全文索引
inner join --内连接
containstable(Sample,[Column],'"世界" or "末日"',500) as k --含有“世界”和“末日”的前500条记录作为表k
on wiki.fs_wiki_title = k.[key] --连接条件
ORDER BY k.RANK DESC --按照k的rank降序排列,即相似度越高的越靠前
执行结果如下:

可以看到,现在的查询时间已经大大减少,因为我们只返回500条记录,并且这些记录都是与给定的“世界”或“末日”非常接近的。
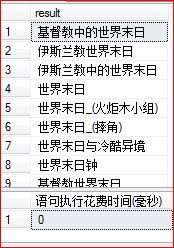
下面,我们可以进行一些更加高级的查询,比如在containstable语法里限定条件,这个时候我们要在库里查含有“世界”并且含有“末日”的所有字符串,执行如下T-SQL语句
SELECT [Column] as [result] From Sample
inner join containstable(Sample,[Column],'"世界" and "末日"',500) as k
on Sample.Column = k.[key]
ORDER BY k.RANK DESC
执行结果如下:
继续,我们再限定查找字符串长度小于等于6,执行如下T-SQL语句
SELECT [Column] as [result] From Sample
inner join containstable(Sample,[Column],'"世界" and "末日"',500) as k
on Sample.Column = k.[key]
where len([Column])<=6
ORDER BY k.RANK DESC
执行结果如下:
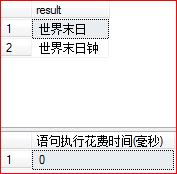
可以看到,这个时候返回结果就很精确了,因此我们通过containstable能够非常灵活的进行查询设计并且对返回结果按相似度排序。freetexttable的用法和containstable用法类似,因此这里不再讲解。