by shinichi_wtn
2009-11-26 19:40
本科生科研基金项目最近进入了实例化阶段,需要将之前的成果做一个展示的平台,也就是我之前提到的“校园维基百科模糊查询平台”,充分利用了我们项目的成果和维基百科的接口。下面谈谈这一个星期的一些进展:可以先到http://www.bnubaike.cn/wiki.aspx体验后再阅读下文
早在一年前,我就想过利用维基百科作为海量数据库的数据源,因为它的词条规模很大,中文有几十万级别,英文则达到千万级别。当时我想过制作离线维基,并下载了维基百科定期dump的xml文件,还自己写了个xml分割器将其分割成几千个小文件并建立索引,不过由于时间关系,最终没有付诸实践。
现在好了,借着科研的时间,可以开始真正花一些功夫了。并且仔细阅读了维基百科的接口(Wikipedia API)
中文维基API:http://zh.wikipedia.org/w/api.php
英文维基API:http://en.wikipedia.org/w/api.php
阅读了外国一些人的博客,发现也有自己想调用维基词条数据的,和我的想法正好类似。但是真正有启发的只有一篇文章,他自己写的一个dojo的插件,叫WikipediaStore,可以直接获取维基百科的词条数据,并展示了一个demo(http://archive.dojotoolkit.org/nightly/dojotoolkit/dojox/data/demos/demo_WikipediaStore.html)
但是这个demo很不完善,但是指引了一条思路。不过我不打算使用dojo,毕竟我不太喜欢使用现成的JS框架,而且dojo有80k,加载会很费时间!相比来说Jquery则轻量得多。由于我开发的BNU校园百科集成了我自己的AJAX的框架,所以我就不引用其他的类库了,直接用我自己写的类库即可。
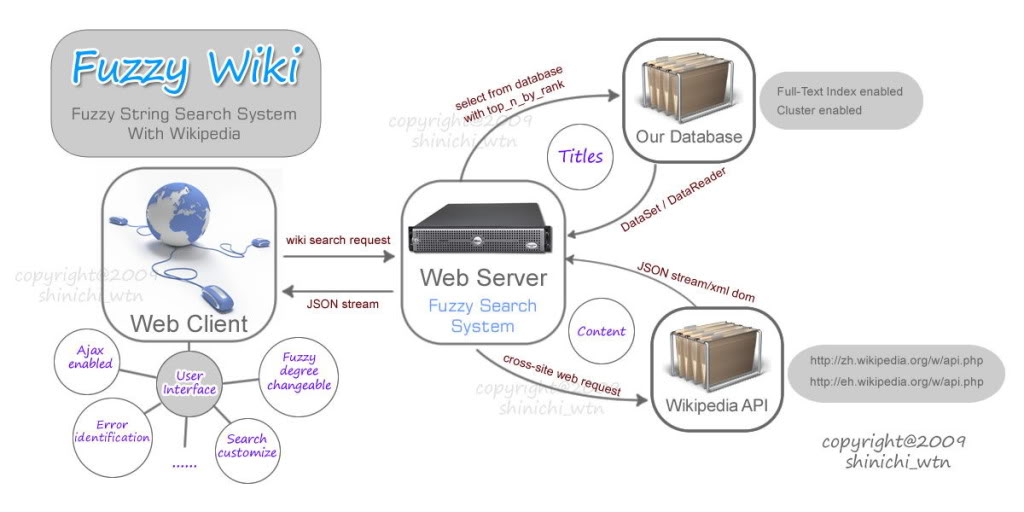
最重要的工作就是弄明白维基百科的开放接口,我花了半天时间认真阅读,并且实践每一个功能,发现很强大,根本没有必要下载数据制作离线维基,只要进行webrequest一切资源都搞定,我不打算用客户端的跨域请求,而直接通过服务器进行请求,这样客户端就能从服务器得到request回来的并且经过处理的数据。
维基百科提供了很多数据类型的返回方式,包括我最喜欢的JSON和XML两种数据,由于要在服务器端对数据进行处理,我选用了XML,返回的Stream直接加载到XmlDocument中,利用XPath直接得到指点节点的文本,然后用正则表达式对文本进行处理,比如替换链接、CSS样式,如此一来,维基词条的内容就能呈现给客户端了。
下面简单说说我设计的维基百科模糊查询系统的构架:
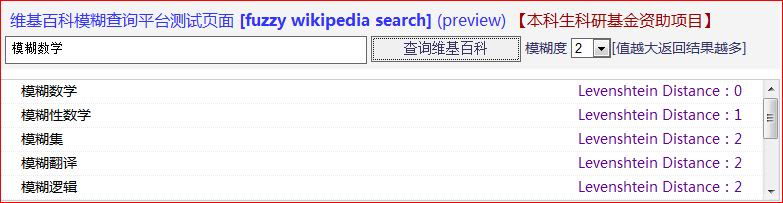
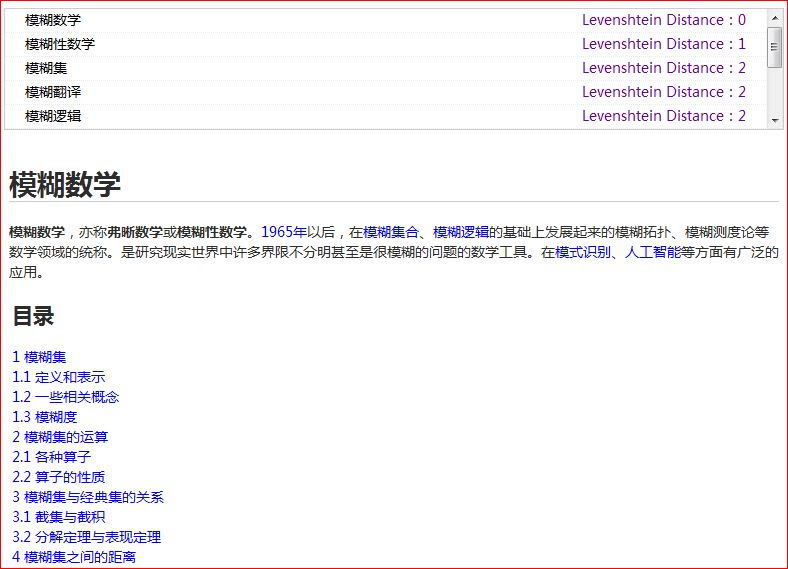
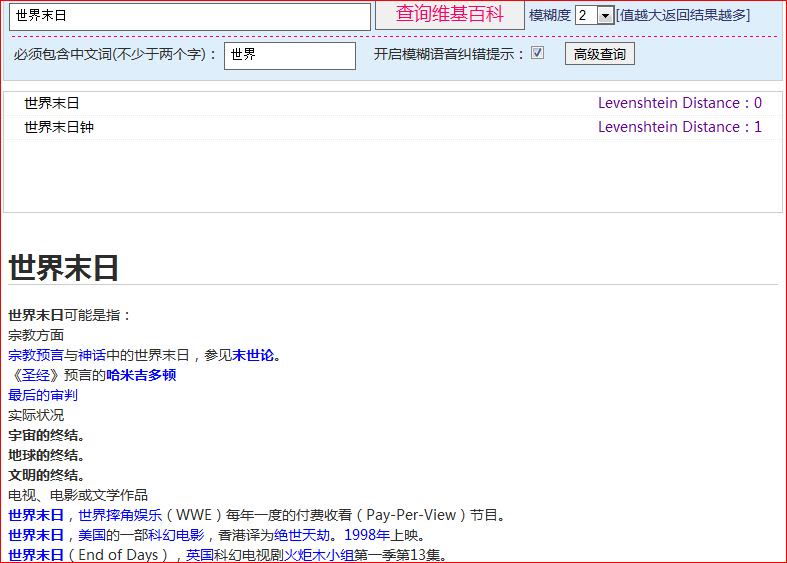
由于现有的维基百科不支持模糊查询,比如用户打错了字,少打了字等等,则找不到相应的词条,所以我们的任务就是在海量词条标题里寻找与用户输入的词条名称最为接近的一些词条,作为搜索建议提供给用户。
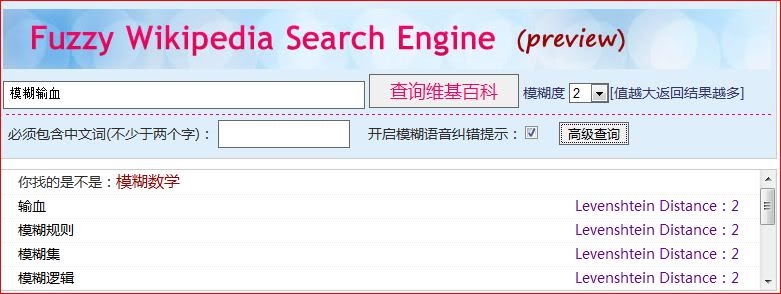
在设计查询界面(UI)的时候,我们需要实现用户搜索定制,包括“模糊度”(类似于隶属度)的调节,模糊度越大返回的结果越多;同样我们需要实现错误修正,主要是由于拼音输入法造成的“同音字词”错误,这个可以通过词频来提供建议;另外,我们还需要制作一些人性化的搜索模块,比如“必须包含字词”。
维基百科接口并没有提供词条的模糊搜索功能,它的仅仅类似于数据库查询时候的 like '%keyword%',一旦keyword输入错误,搜索就失败了。为了实现真正的模糊搜索,我们采用词条标题与内容分离的方法,我们在自己的库中只存储词条标题,并建立多个索引,包括全文索引,在查询的时候利用我们定义的隶属函数,返回高于给定阈值的字符串集合,当然是排好序的。
整个中文维基百科模糊查询实例大概就是这样,预览平台:http://www.bnubaike.cn/wiki.aspx
现在仍在开发中,目前提供仅是预览版,最初搜索定制功能还不完善(只有模糊度),2009年12月10日更新高级查询,增加必含词与语音纠错功能,当然,我会继续开发下去的,呵呵!放几张图吧(现在服务器变成教育网了,不能进行跨域请求了,所以暂时不提供词条内容显示,而是直接提供链接)
以下为2009年12月10日更新
 <
<
以下为11月26日更新